运算操作
算术运算
data['open'].add(1)
2018-02-27 24.53
2018-02-26 23.80
2018-02-23 23.88
2018-02-22 23.25
2018-02-14 22.49
逻辑运算
1> 逻辑运算符号
data["open"] > 23
2018-02-27 True
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
# 逻辑判断的结果可以作为筛选的依据
data[data["open"] > 23].head()
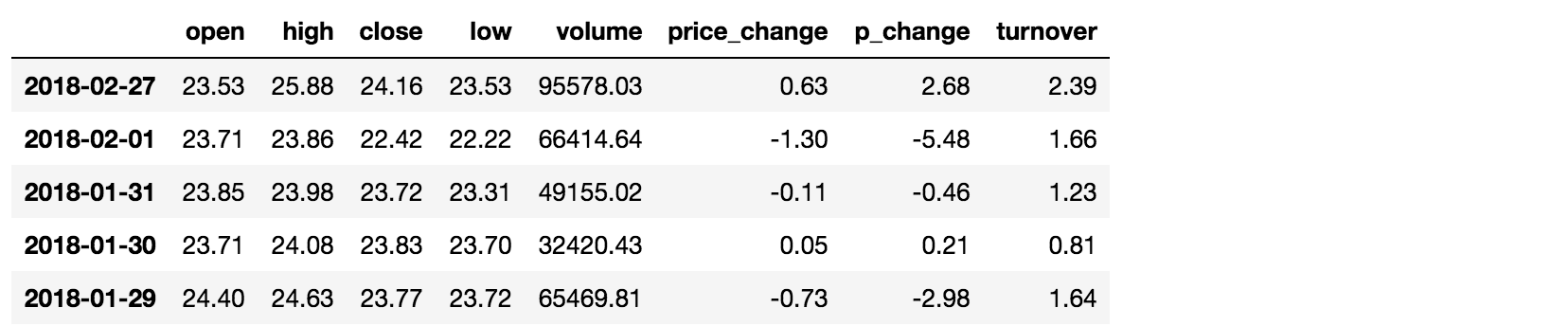
data[(data["open"] > 23) & (data["open"] < 24)].head()
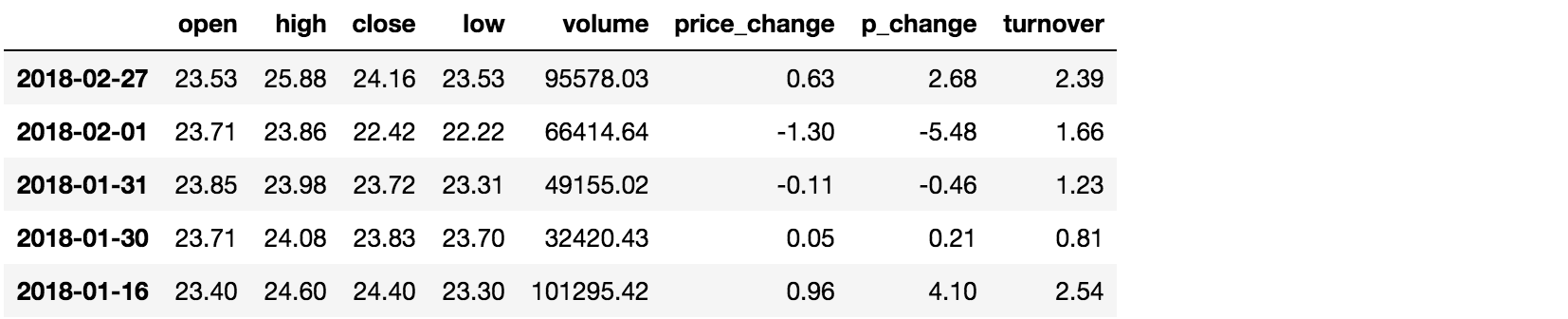
2> 逻辑运算函数
query(expr)
data.query("open<24 & open>23").head()
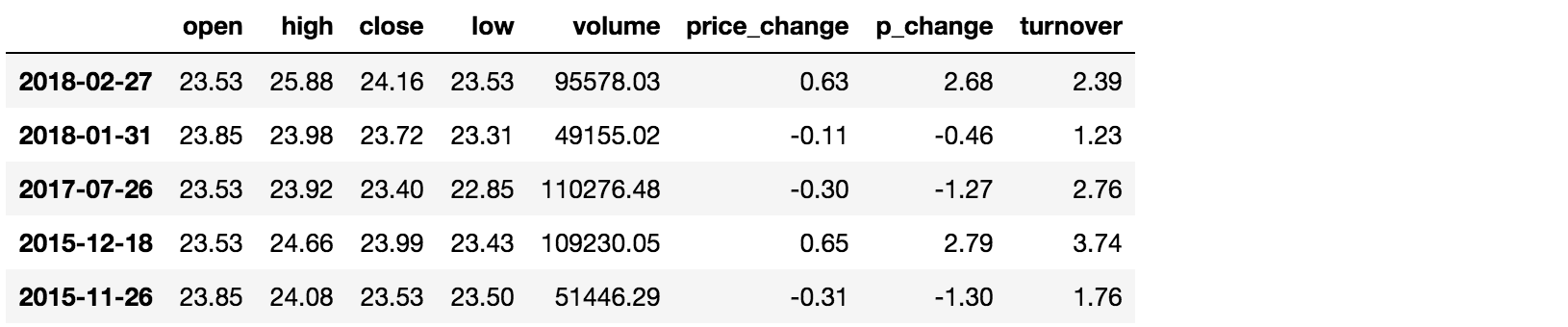
# 可以指定值进行一个判断,从而进行筛选操作
data[data["open"].isin([23.53, 23.85])]
函数应用
- 表格函数 : pipe()
- 行列合理函数 : apply()
- 元素合理函数 : applymap()
1> 表格函数
def add_num(ele1, ele2):
return ele1 + ele2
df = pd.DataFrame(np.random.randn(2,3), columns=['col1','col2','col3'])
print(f'原始数组:\n{df}')
# 输出结果:
# 原始数组:
# col1 col2 col3
# 0 -0.969587 -1.668058 -0.063144
# 1 -1.112474 1.006431 1.003687
print(f'调用函数后:\n{df.pipe(add_num,2)}')
# 输出结果:
# 调用函数后:
# col1 col2 col3
# 0 1.030413 0.331942 1.936856
# 1 0.887526 3.006431 3.003687
2> 行列合理函数
在默认情况下,操作按列执行,将每列列为数组
df = pd.DataFrame(np.random.randn(2,3), columns=['col1','col2','col3'])
print(f'原始数组:\n{df}')
# 输出结果:
# 原始数组:
# col1 col2 col3
# 0 1.044008 -0.694310 -0.65942
# 1 1.074292 1.051992 1.68558
df1 = df.apply(np.mean)
print(f'调用函数后:\n{df1}')
# 输出结果:
# 调用函数后:
# col1 1.059150
# col2 0.178841
# col3 0.513080
# dtype: float64
使用 lambda 作为参数:
df = pd.DataFrame(np.random.randn(2,3), columns=['col1','col2','col3'])
print(f'原始数组:\n{df}')
# 输出结果:
# 原始数组:
# col1 col2 col3
# 0 -1.437103 -0.408853 -1.184260
# 1 1.325277 -0.979137 0.497137
df1 = df.apply(lambda x : x.max()-x.min() ,axis = 1)
print(f'调用函数后:\n{df1}')
# 输出结果:
# 调用函数后:
# 0 1.028250
# 1 2.304415
# dtype: float64
3> 元素合理函数
DataFrame 的 applymap()函数和 Series 的 map()函数
df = pd.DataFrame(np.random.randn(2,3), columns=['col1','col2','col3'])
print(f'原始数组:\n{df}')
# 输出结果:
# 原始数组:
# col1 col2 col3
# 0 0.286482 0.381885 1.904780
# 1 1.598254 0.856874 -0.166022
df1 = df['col1'].map(lambda x:x*100)
print(f'应用函数后:\n{df1}')
# 输出结果:
# 应用函数后:
# 0 28.648158
# 1 159.825408
# Name: col1, dtype: float64
df1 = df.applymap(lambda x:x*100)
print(f'应用函数后:\n{df1}')
# 输出结果:
# 应用函数后:
# col1 col2 col3
# 0 66.045303 -196.886843 17.495741
# 1 -51.407796 -57.917430 161.074754